 盘古低代码
盘古低代码Kafka
入门指南
1.1概述
什么是事件流?
事件流相当于人体的中枢神经系统的数字化。它是 "永远在线 "世界的技术基础,在这个世界里,业务越来越多地被软件定义和自动化,软件的用户更是软件。
从技术上讲,事件流是指以事件流的形式从数据库、传感器、移动设备、云服务和软件应用等事件源中实时捕获数据;将这些事件流持久地存储起来,以便日后检索;对事件流进行实时以及回顾性的操作、处理和反应;并根据需要将事件流路由到不同的目的技术。因此,事件流确保了数据的连续流动和解释,从而使正确的信息在正确的时间和地点出现。
可以使用事件流做什么?
事件流应用于众多行业和组织的各种用例。它的许多例子包括:
- 实时处理支付和金融交易,比如在证券交易所、银行和保险公司
- 实时跟踪和监控汽车、卡车、车队和货物,如物流和汽车行业。
- 持续采集和分析来自物联网设备或其他设备的传感器数据,例如在工厂和风场。
- 收集并立即响应客户的互动和订单,例如在零售、酒店和旅游行业以及移动应用中。
- 监测医院护理中的病人,并预测病情变化,以确保紧急情况下的及时治疗。
- 连接、存储和提供公司不同部门产生的数据。
- 作为数据平台、事件驱动架构和微服务的基础。
Apache Kafka是一个分布式流媒体平台。这到底是什么意思呢?
一个流式平台有三个关键能力。
- 发布和订阅记录流,类似于消息队列或企业消息系统。
- 以容错耐用的方式存储记录流。
- 在记录流发生时进行处理。
Kafka一般用于两大类应用。
- 构建实时流数据管道,在系统或应用之间可靠地获取数据。
- 构建实时流媒体应用程序,转换或反应数据流。
Kafka是如何工作的?
Kafka是一个分布式系统,由服务器和客户端组成,通过高性能的TCP网络协议进行通信。它可以部署在内部以及云环境中的裸机硬件、虚拟机和容器上。
- 服务器。Kafka以一个或多个服务器集群的形式运行,可以跨越多个数据中心或云区域。这些服务器中的一些构成了存储层,称为经纪人。其他服务器运行Kafka Connect,以事件流的形式持续导入和导出数据,将Kafka与您现有的系统(如关系型数据库以及其他Kafka集群)集成。为了让您实现关键任务用例,Kafka集群具有高度的可扩展性和容错性:如果它的任何一台服务器发生故障,其他服务器将接管它们的工作,以确保在没有任何数据丢失的情况下连续运行。
- 客户端。它们允许你编写分布式应用和微服务,即使在网络问题或机器故障的情况下,也能以并行、大规模、容错的方式读取、写入和处理事件流。Kafka船载包含了一些这样的客户端,Kafka社区提供的几十个客户端对其进行了增强:客户端可用于Java和Scala,包括更高级别的Kafka Streams库,用于Go、Python、C/C++和许多其他编程语言,以及REST API。
主要概念和术语
事件记录了世界上或你的企业中 "发生了什么 "的事实。它在文档中也被称为记录或消息。当你向Kafka读写数据时,你是以事件的形式进行的。概念上,一个事件有一个键、值、时间戳和可选的元数据头。下面是一个事件的例子。
- 事件键:"Alice"
- 事件价值: "支付了200美元给鲍勃"
- 事件时间戳: "2020年6月25日下午2点06分"
生产者(Producers)是那些向Kafka发布(写)事件的客户端应用,消费者是那些订阅(读取和处理)这些事件的应用。在Kafka中,生产者和消费者是完全解耦的,彼此不可知,这是实现Kafka闻名的高可扩展性的关键设计元素。例如,生产者从来不需要等待消费者。Kafka提供了各种保证,例如,能够精确地处理事件-once。
事件(Events)被组织并持久地存储在主题中。非常简化,一个topic类似于文件系统中的一个文件夹,而事件就是该文件夹中的文件。一个例子的topic名称可以是 "支付"。Kafka中的topic总是多生产者和多订阅者的:一个topic可以有零个、一个或许多生产者向它写入事件,也可以有零个、一个或许多消费者订阅这些事件。话题中的事件可以根据需要随时读取--与传统的消息系统不同,事件在消耗后不会被删除。相反,你可以通过每个主题的配置设置来定义Kafka应该保留你的事件多长时间,之后旧的事件将被丢弃。Kafka的性能与数据大小有效地保持不变,所以长时间存储数据是完全可以的。
话题(Topics)是分区的,也就是说一个话题会分布在位于不同的Kafka经纪商上的多个 "桶 "上。这种数据的分布式放置对可扩展性非常重要,因为它允许客户端应用程序同时从/向许多经纪商读写数据。当一个新的事件发布到一个主题时,它实际上被附加到主题的一个分区中。具有相同事件键的事件(例如,客户或车辆ID)被写入同一分区,Kafka保证给定主题分区的任何消费者将始终以与事件写入顺序完全相同的方式读取该分区的事件。
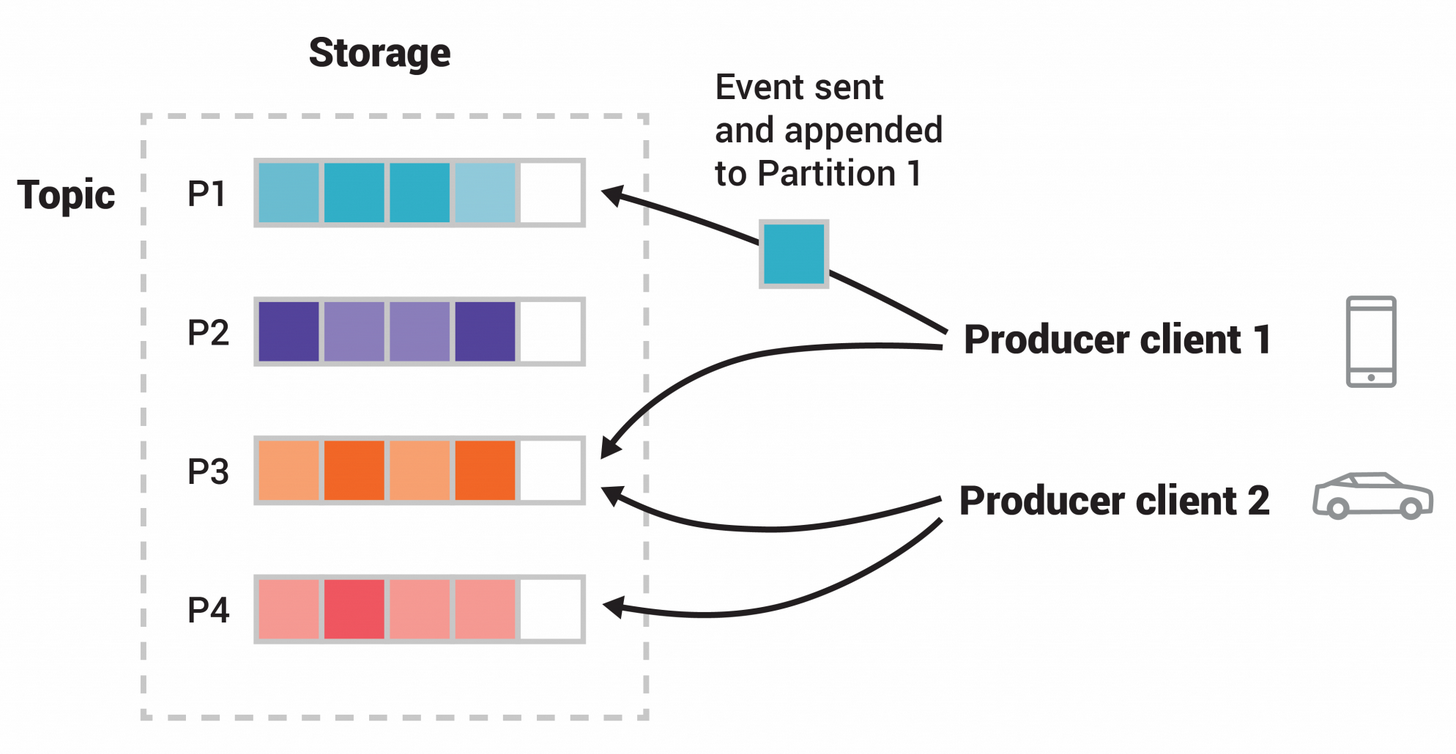
示例
图中主题有四个分区P1-P4。两个不同的生产者客户端通过网络将事件写入主题的分区,彼此独立地发布新事件到主题。具有相同键的事件(图中用它们的颜色表示)被写入同一个分区。注意,如果合适的话,两个生产者都可以写到同一个分区。
为了使你的数据具有容错性和高可用性,每个主题都可以被复制,甚至可以跨地理区域或数据中心,这样总有多个broker拥有数据的副本,以防万一出现问题,你想对broker进行维护等等。常见的生产设置是复制系数为3,即你的数据永远有三个副本。这种复制是在主题-分区的层面上进行的。
这个初级介绍应该足够了。如果你有兴趣的话,文档中的设计部分会完整详细地解释Kafka的各种概念。
为了了解Kafka是如何做这些事情的,我们从底层开始深入探讨Kafka的能力。
先说几个概念。
- Kafka以集群的形式运行在一个或多个服务器上,可以跨越多个数据中心。
- Kafka集群以称为主题的类别存储记录流。
- 每条记录由一个键、一个值和一个时间戳组成。
Kafka有四个核心API。
- 生产者API允许应用程序将记录流发布到一个或多个Kafka主题中。
- 消费者API允许应用程序订阅一个或多个主题,并处理向其产生的记录流。
- Streams API允许应用程序作为一个流处理器,消耗一个或多个主题的输入流,并产生一个输出流到一个或多个输出主题,有效地将输入流转换为输出流。
- 连接器API允许构建和运行可重复使用的生产者或消费者,将Kafka主题连接到现有的应用程序或数据系统。例如,关系型数据库的连接器可能会捕获表的每一个变化。
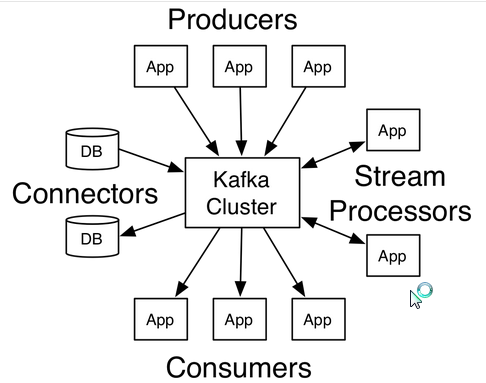
1.2使用案例
以下是对Apache Kafka®的一些流行用例的描述。关于这些领域的概述,请看这篇博客文章。
讯息传递
Kafka可以很好地替代更传统的消息中介。消息经纪人的使用有多种原因(将处理与数据生产者解耦,缓冲未处理的消息等)。与大多数消息系统相比,Kafka具有更好的吞吐量、内置的分区、复制和容错能力,这使得它成为大规模消息处理应用的良好解决方案。 根据我们的经验,消息处理的用途往往是比较低的吞吐量,但可能需要较低的端到端延迟,并且往往依赖于Kafka提供的强大的耐久性保证。
在这个领域中,Kafka可以和传统的消息系统,如ActiveMQ或RabbitMQ相媲美。
网站活动跟踪
Kafka最初的用例是能够将用户活动跟踪管道重建为一组实时发布-订阅feeds。这意味着网站活动(页面浏览、搜索或用户可能采取的其他行动)被发布到中心主题,每个活动类型有一个主题。这些feed可供订阅,用于一系列用例,包括实时处理、实时监控以及加载到Hadoop或离线数据仓库系统中进行离线处理和报告。
活动跟踪通常是非常大量的,因为每个用户页面浏览都会产生许多活动消息。
衡量标准
Kafka经常用于运营监控数据。这涉及到从分布式应用中聚合统计数据,以产生集中的运营数据源。
日志聚合
许多人使用Kafka作为日志聚合解决方案的替代品。日志聚合通常会从服务器上收集物理日志文件,并将它们放在一个中心位置(可能是文件服务器或HDFS)进行处理。Kafka抽象掉了文件的细节,并将日志或事件数据抽象为一个更干净的消息流。这使得处理延迟更低,更容易支持多个数据源和分布式数据消费。与Scribe或Flume等以日志为中心的系统相比,Kafka同样具有良好的性能,由于复制而具有更强的耐久性保证,端到端延迟也低得多。
流处理
Kafka的许多用户在由多个阶段组成的处理管道中处理数据,原始输入数据从Kafka主题中消耗,然后聚合、丰富或以其他方式转化为新的主题,以便进一步消耗或后续处理。例如,用于推荐新闻文章的处理管道可能会从RSS订阅中抓取文章内容,并将其发布到 "文章 "主题中;进一步的处理可能会对这些内容进行归一化或重复数据化,并将清洗后的文章内容发布到新的主题中;最后的处理阶段可能会尝试向用户推荐这些内容。这样的处理流水线会根据各个主题创建实时数据流的图。从0.10.0.0开始,Apache Kafka中提供了一个轻量级但功能强大的流处理库Kafka Streams,用于执行上述此类数据处理。除了Kafka Streams,其他的开源流处理工具还包括Apache Storm和Apache Samza。
事件源
事件源是一种应用设计风格,其中状态变化被记录为一个时间顺序的记录序列。Kafka对非常大的存储日志数据的支持使其成为以这种风格构建的应用程序的优秀后端。
提交日志
Kafka可以作为分布式系统的一种外部提交日志。该日志有助于在节点之间复制数据,并作为失败节点的重新同步机制,以恢复其数据。Kafka中的日志压缩功能有助于支持这种用法。在这个用法上,Kafka类似于Apache BookKeeper项目。
APIS
Kafka包括五个核心API。
- 生产者API允许应用程序向Kafka集群中的主题发送数据流。
- Consumer API允许应用程序从Kafka集群中的主题读取数据流。
- Streams API允许将数据流从输入主题转换为输出主题。
- 连接API允许实现连接器,不断地从一些源系统或应用拉入Kafka,或从Kafka推入一些汇系统或应用。
- 管理API允许管理和检查主题、broker和其他Kafka对象。
Kafka通过一个独立于语言的协议公开其所有功能,该协议有许多编程语言的客户端。然而,只有Java客户端是作为Kafka主项目的一部分来维护的,其他的客户端是作为独立的开源项目来提供的。非Java客户端的列表可以在这里找到。
2.1 Producer API
Producer API允许应用程序向Kafka集群中的主题发送数据流。
在javadocs中给出了如何使用producer的例子。
要使用producer,你可以使用以下maven依赖。
java
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.7.0</version>
</dependency>2.2 Consumer API
消费者API允许应用程序从Kafka集群中的主题读取数据流。
javadocs中给出了如何使用消费者的例子。
要使用消费者,你可以使用以下maven依赖。
java
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.7.0</version>
</dependency>2.3 Streams API
Streams API允许将数据流从输入主题转换为输出主题。
在javadocs中给出了如何使用这个库的例子。
关于使用Streams API的其他文档在这里提供。
要使用Kafka Streams,你可以使用以下maven依赖。
java
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>2.7.0</version>
</dependency>当使用Scala时,你可以选择包含kafka-streams-scala库。关于使用Kafka Streams DSL for Scala的其他文档请参见开发者指南。
要使用Kafka Streams DSL for Scala for Scala 2.13,你可以使用以下maven依赖。
java
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams-scala_2.13</artifactId>
<version>2.7.0</version>
</dependency>2.4 Connect API
Connect API允许实现连接器,不断地从一些源数据系统拉入Kafka,或者从Kafka推送到一些汇数据系统。
很多Connect的用户不需要直接使用这个API,不过,他们可以使用预建的连接器,而不需要编写任何代码。
关于使用Connect的其他信息可以在这里获得。
想要实现自定义连接器的用户可以查看javadoc。
2.5 Admin API
管理API支持管理和检查主题、经纪人、acls和其他Kafka对象。
要使用Admin API,请添加以下Maven依赖关系。
java
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.7.0</version>
</dependency>有关Admin APIs的更多信息,请参阅javadoc。
demo样例
- 生产者demo
java
public class KafkaProducerTest {
public static void main(String[] args) {
Properties props = new Properties();
props.put("serializer.class", "kafka.serializer.StringEncoder");
props.put("metadata.broker.list", "xxx.xxx.xxx.xxx:9092");
props.put("enable.auto.commit", "false");
Producer<Integer, String> producer = new Producer<Integer, String>(new ProducerConfig(props));
String topic = "test";
File file = new File("C:/Users/test_user/Downloads/kafka-data/test.txt");
BufferedReader reader = null;
try {
reader = new BufferedReader(new FileReader(file));
String tempString = null;
int line = 1;
while ((tempString = reader.readLine()) != null) {
producer.send(new KeyedMessage<Integer, String>(topic,tempString));
System.out.println("Success send [" + line + "] message ..");
line++;
}
reader.close();
System.out.println("Total send [" + line + "] messages ..");
} catch (Exception e) {
e.printStackTrace();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e1) {}
}
}
producer.close();
}
}- 消费者demo
java
public class KafkaConsumerTest {
public static void main(String[] args) {
String topic = "test";
ConsumerConnector consumer = Consumer.createJavaConsumerConnector(createConsumerConfig());
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, new Integer(1));
Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);
KafkaStream<byte[], byte[]> stream = consumerMap.get(topic).get(0);
ConsumerIterator<byte[], byte[]> it = stream.iterator();
while(it.hasNext())
System.out.println("consume: " + new String(it.next().message()));
}
private static ConsumerConfig createConsumerConfig() {
Properties props = new Properties();
props.put("group.id","grouptest");
props.put("zookeeper.connect","xxx.xxx.xxx.xxx:2181");
props.put("zookeeper.session.timeout.ms", "100000");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
props.put("enable.auto.commit", "false");
return new ConsumerConfig(props);
}
}