 盘古低代码
盘古低代码日志收集组件
介绍
Filebeat是用于转发和集中日志数据的轻量级传送工具。Filebeat监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash进行索引。
Filebeat的工作方式
启动Filebeat时,它将启动一个或多个输入,这些输入将在为日志数据指定的位置中查找。对于Filebeat所找到的每个日志,Filebeat都会启动收集器。每个收集器都读取单个日志以获取新内容,并将新日志数据发送到libbeat,libbeat将聚集事件,并将聚集的数据发送到为Filebeat配置的输出。
部署
云平台部署
1.云平台有fileBeat镜像,直接通过镜像仓库部署即可,部署后需要在被收集日志应用下,挂载存储,把日志文件存到该存储下,如下: 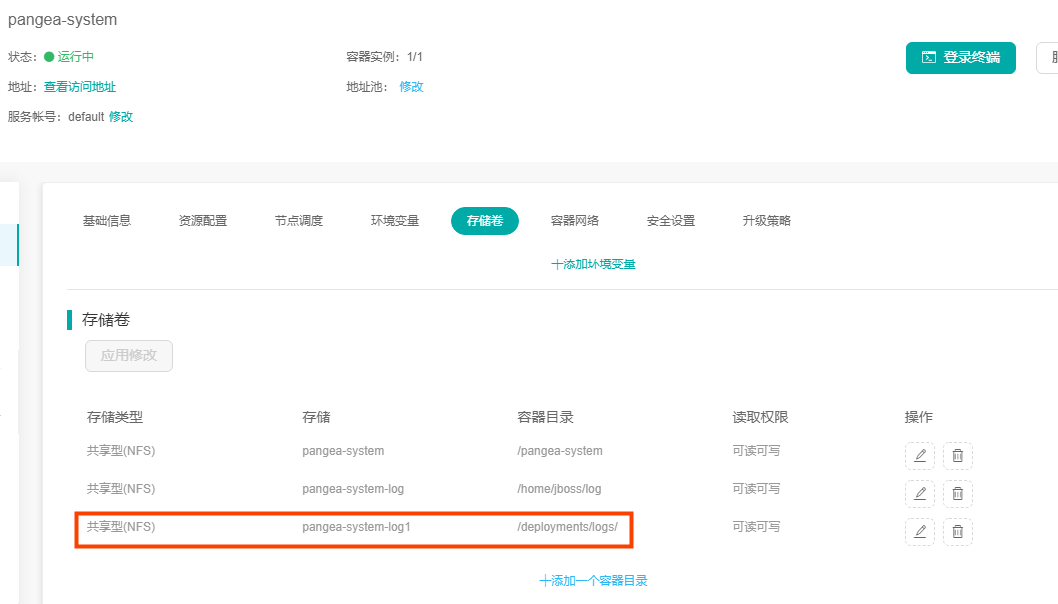
2.filebeat部署之后需要从该存储下读文件: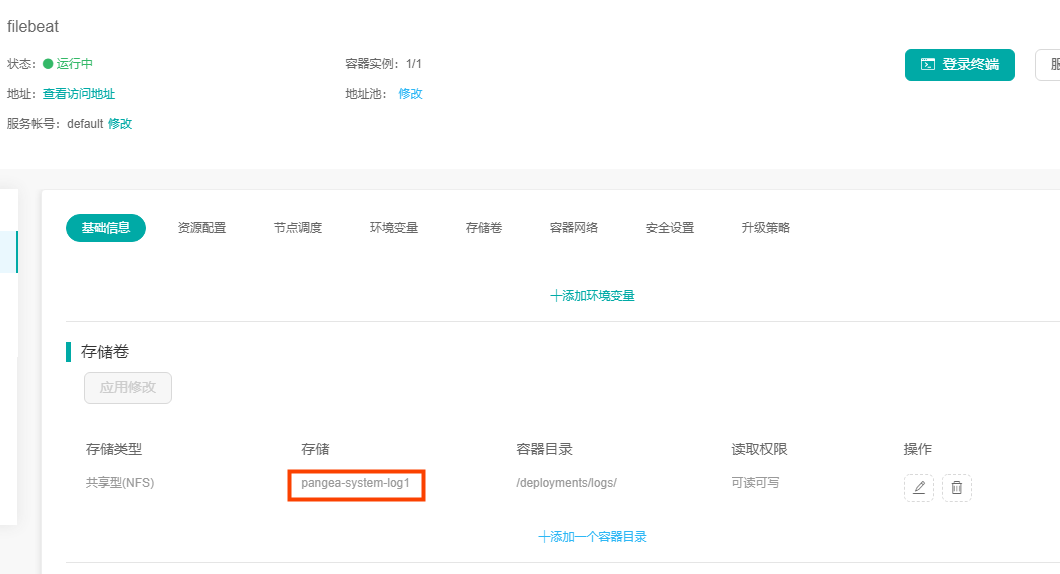
3.fileBeat需要挂载配置文件,文件中配置如下:
xml
filebeat.prospectors:
- input_type: log
enabled: true
paths:
# 指定存储地址下取哪些文件
- /deployments/logs/web_*.log
json.keys_under_root: true
json.add_error_key: true
json.message_key: log
processors:
- add_cloud_metadata:
# 指定输出到elasticSearch的地址
output.elasticsearch:
hosts: ['10.19.46.34:9200']
#指定生成index的命名规范
index: "system_dev_log-%{+yyyy.MM}"
username:
password:4.fileBeat指定elasticSearch的索引,如果不做处理会提示找不到索引,需要在elasticSearch建立相应索引,或者设置成自动创建索引。关于elasticSearch的相关操作,请参见elasticSearch组件文章。
查询
数据直接推送到elasticSearch,可以通过部署kinaba来查询elasticSearch中的数据,可以看到推过来的数据: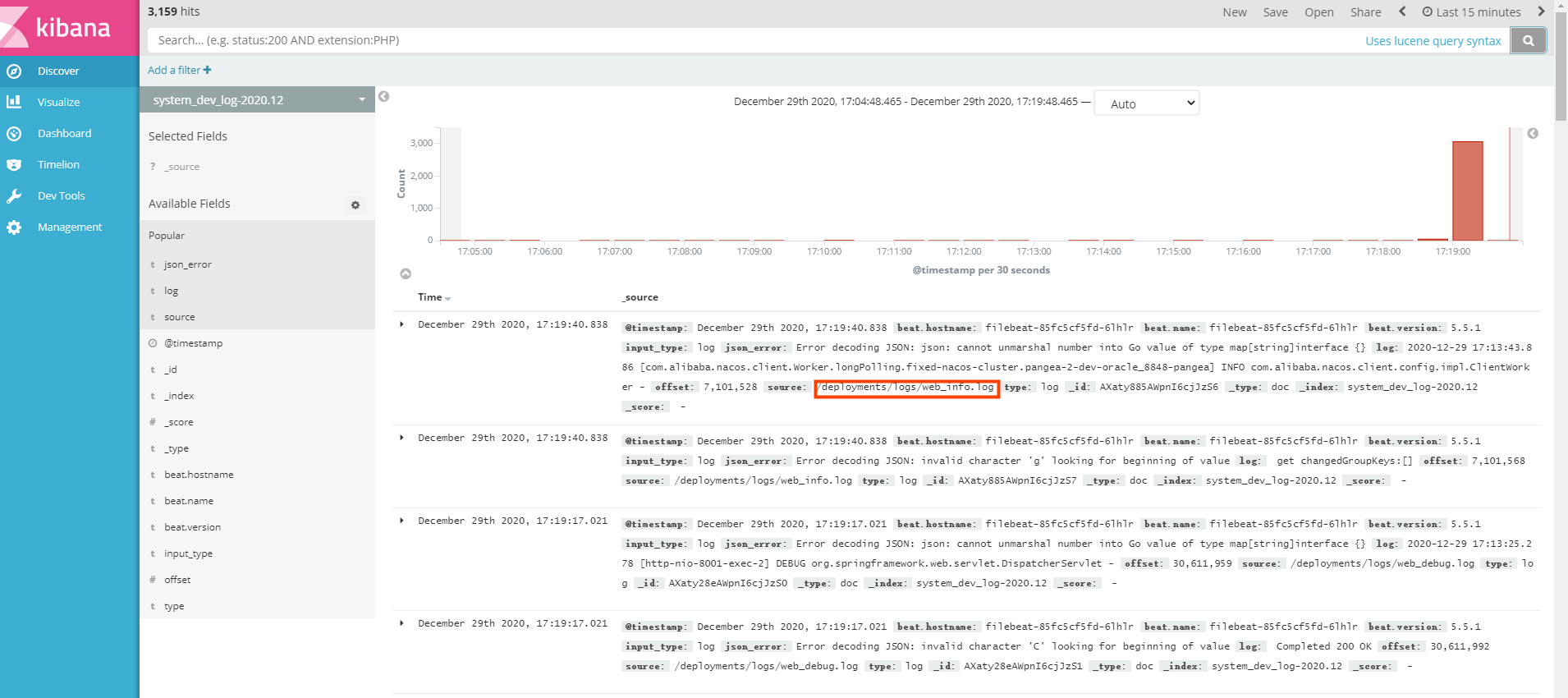
fileBeat调优
Filebeat 的缓存目前分为 memqueue 和 spool。memqueue 顾名思义就是内存缓存,spool 则是将数据缓存到磁盘中
1.memqueue
可配置的 全局参数 max_procs: 1 # 限制一个CPU核心,避免过多抢占业务资源
queue.mem.events: 2048 # 存储于内存队列的事件数,排队发送 (默认4096)
queue.mem.flush.min_events: 1536 # 小于 queue.mem.events ,增加此值可提高吞吐量 (默认值2048)
queue.mem.flush.timeout: 1s # 这是一个默认值,到达 min_events 需等待多久刷出
2.spool
xml
queue.spool.file:
path: "${path.data}/spool.dat" #spool文件的位置, 默认的位置是 ${path.data}/spool.dat
size: 512MiB # 文件大小提示, 一旦达到这个极限, spool 阻塞
page_size: 16KiB # 一个文件被分割成相同大小的多个页面 默认值是4KiB
prealloc #如果prealloc设置为true,则使用truncate将空间保留到文件大小.此设置仅在创建文件时使用。如果prealloc设置为false,文件将动态增长。如果prealloc为false且系统磁盘空间不足,则假脱机将阻塞。默认值为true。
queue.spool.write:
buffer_size: 10MiB # 设置 write buffer 大小
flush.timeout: 5s # 如果写缓冲区尚未满, 刷新事件的最大等待时间
flush.events: 1024 # 最大缓冲事件数。一旦达到限制,写缓冲区就会被刷新。
flush.codec: cbor # 用于序列化事件的事件编码。有效值为json和cbor。默认值为cbor。
queue.spool.read:
flush.timeout: 0s #如果 flush_timeout 为 0, 则立即将所有可用事件转发到输出。注意
如果想用一个fileBeat收集多个应用的日志,只要在部署的第一步中,把这几个应用的日志都推到fileBeat的存储即可,注意日志名称要有区分,以及fileBeat采集日志文件的名称要能读到全部需要收集的日志文件。