盘古低代码
盘古低代码监控告警
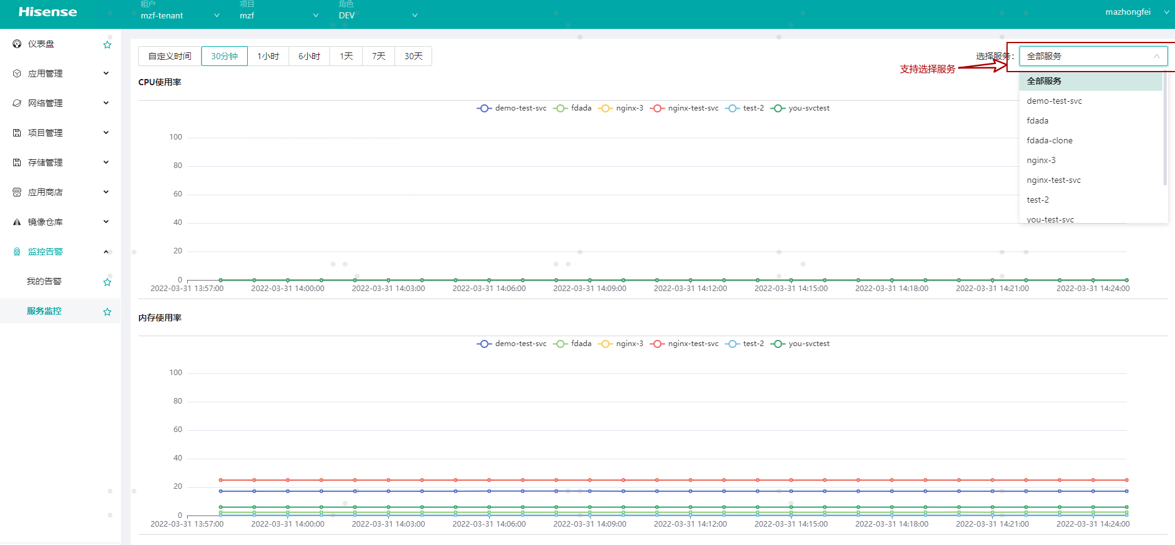
服务监控
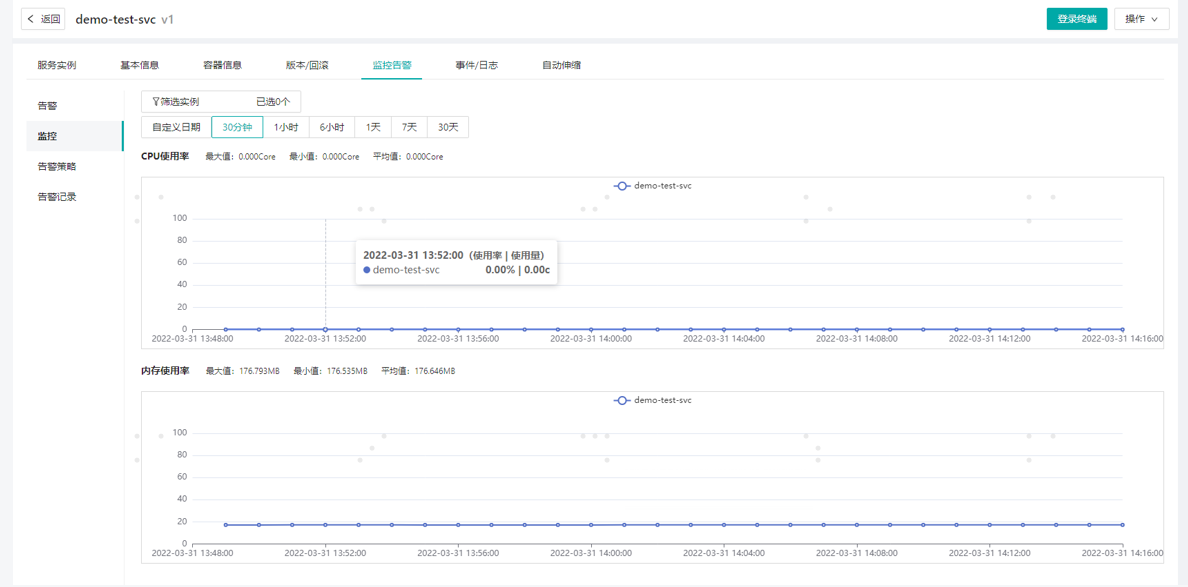
信云+会采集服务pod、容器的CPU、内存、网络IO的监控信息,并以折线图的形式在前端展示出来: 查看服务监控有两个入口,1是服务详情内查看当前服务的监控信息,2是在【监控告警】-【服务监控】内查看整个项目所有服务的监控信息,此页面也可单独查看某个服务的信息;进入后默认展示当前服务所有pod平均的cpu使用率/使用量、内存使用率/使用量; 可单独选择1个或多个pod查看监控信息,网络io监控信息在单独选择pod后才会展示出来; 也可单独查看pod某个容器的监控信息; 支持按时间区间过滤。
我的告警
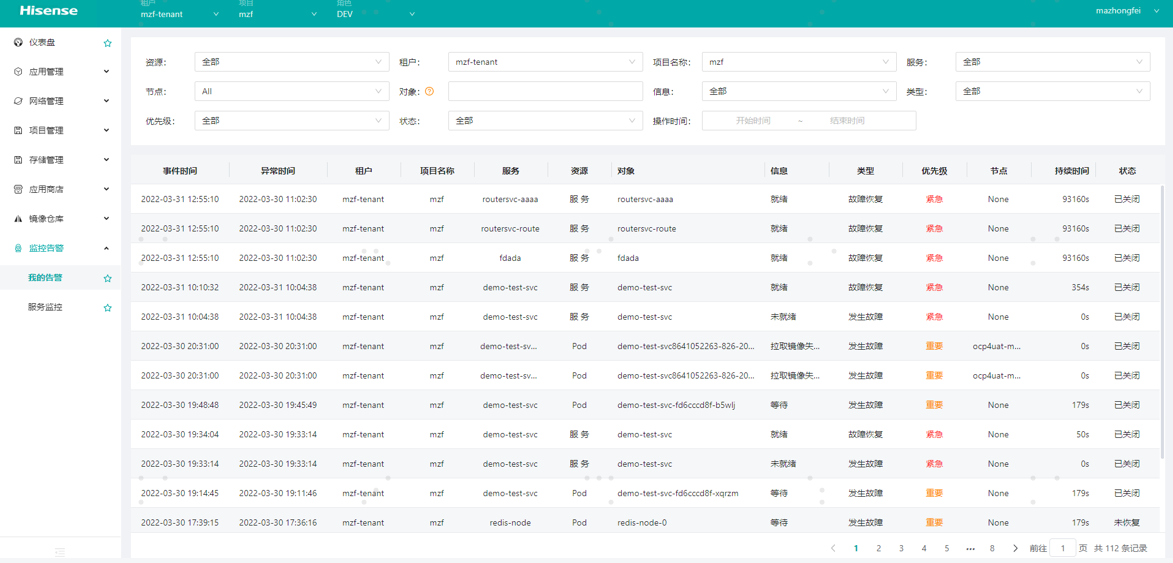
信云+监控Pod、Endpoints、Node等资源的状态变化,根据发现的异常情况进行告警,在页面上也会显示对应的告警信息,具体信息如下
- resource:资源类型,分为Pod/容器组,Service/服务,Node/节点,IDC/机房,
- object:对象名,对应于上述Pod, Service, Node, IDC资源类型,分别为pod名,服务名,节点名,机房名,
- priority:告警级别,从高到低依次为:Critical/紧急,Major/重要,Normal/普通,Minor/低,
- info:具体告警信息:以下列举部分告警信息,供参考。
对于resource=Pod:
- Pending/等待:此pod目前没有可调度的节点,正等待调度(超过3分钟上报告警);
- ErrImagePull/拉取镜像失败:从harbor拉取镜像失败,可能是镜像被删除或权限不足等原因;
- ImagePullBackOff/拉取镜像失败退避:尝试重新拉取镜像前的退避等待期;
- ContainersNotReady/容器未就绪:此pod中容器未通过readiness健康检查,不能对外提供服务(超过3分钟上报告警);
- ContainerCannotRun/容器无法运行:容器已创建但未正常启动,可能是docker服务存在异常等原因;
- RunContainerError/运行容器故障:通过docker runtime启动容器出现异常,可能是docker服务存在异常等原因;
- Error/错误:容器结束运行,退出码非0(异常退出、程序崩溃)
- Completed/运行结束:容器结束运行,退出码为0;
- CrashLoopBackOff/容器程序崩溃:尝试重启退出的容器前的退避等待期,最长5分钟,可结合信云+服务界面事件(event)查看具体退避时间;
- Out Of Disk/磁盘已满:节点报告磁盘已满,拒绝继续运行此pod(kubelet重启后对其所在节点上pod会报告此状态,这些服务的pod会重新调度);
- NodeLost/节点丢失:DaemonSet pod所在节点处于NotReady状态一定时间后变为NodeLost状态;
- Unknown/未知:pod被要求删除但其节点处于NotReady状态一定时间后变为Unknown状态,平台不能确定此pod目前实际状态;
- Running/正常运行:(故障恢复)pod正常运行;
对于resource=Service:
- NotReady/未就绪:此服务所有pod都未通过readiness健康检查,不能对外提供服务;
- Ready/就绪:此服务已有pod通过健康检查,可以对外提供服务。